Arpeggios & Filter Pings
Intention
The last stretch of sessions ran on two separate tracks. One was arpeggios in session 28 — a chord held still and then unrolled into a moving line, the harmony spelled out one note at a time. The other was resonance in session 30 — filters and resonators struck like bells and left to ring, the filter itself becoming the sound source instead of a tool carving an oscillator.
This session is the first time I try to put those two studies in the same rack and have them play together as one patch rather than as isolated experiments. The goal isn’t a new technique — it’s combination: fanning the two ideas out into three voices — an arpeggiated line and a held, staticky chord on the arpeggio side, a chance-scattered pinged filter on the resonance side — then giving them a shared clock, a drum floor and one mix, and learning what it takes to make separate studies sound like one piece of music.
The arpeggiated voice, distorted
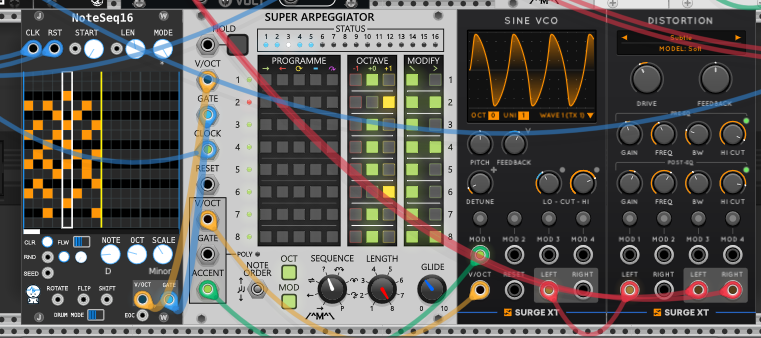
The first voice is the arpeggiator from session 28, carried over whole: NoteSeq16 holds a stacked chord, and the Super Arpeggiator (Count Modula) steps a programmed pattern through it. Accent is flagged per step in its MODIFY column — set on steps 2 and 4 — and fires the arp’s ACCENT output on those steps to drive the Sine VCO’s feedback, so steps 2 and 4 brighten with extra harmonics instead of getting louder — a timbral accent rather than a loudness one. What’s new is the end of the chain. Where session 28 sent the VCO straight to the mixer, here it runs through a Surge XT Distortion, and that’s what lets a single sine oscillator hold its own against the resonant voices coming later.
The distortion is where the voice gets its body. A sine with a little feedback is still a fairly thin, polite tone; the distortion fattens it into something with grit and weight. The MODEL is set to Soft — the gentlest of Surge’s waveshaping curves, a rounded soft-clip that rounds the peaks of the wave rather than slamming them flat, so it adds warmth and harmonic fill without the harsh buzz of a hard-clipping model. DRIVE is how hard the signal gets pushed into that curve: low and it’s nearly clean with just an edge on the loudest steps; turning it up, the sine thickens and starts to grind, picking up overtones and sustaining longer as the saturation compresses the dynamics together. FEEDBACK routes the distorted output back into its own input — a little adds a rougher, hairier edge, and pushed far it tips toward an unstable squeal, the distortion biting its own tail.
The two EQ bands shape the grit on either side of the waveshaper. PRE-EQ is a band of EQ before the distortion, so it decides what gets distorted: GAIN boosts or cuts a band centred at FREQ, BW sets how wide that band is, and HI CUT rolls the top off before the signal hits the curve. Boosting here pushes that band harder into saturation — emphasis becomes grit — while rolling the highs off keeps this sine-based voice from fizzing, so its distortion reads as warm body rather than a harsh hiss that would clash with the bright pings later in the mix. POST-EQ is the same band after the waveshaper, cleaning up the result — taming any harshness or carving the tone once the harmonics are already there, which is where I set how much top end the arp brings to the mix. Pre-EQ sculpts the fuel, post-EQ sculpts the fire.
A chord as pitched static
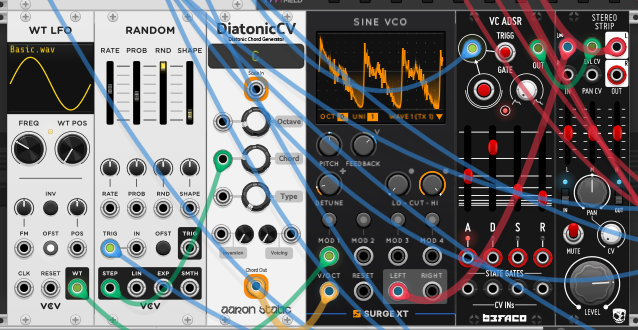
The second voice starts from the same harmonic engine as session 28’s opening patch — RANDOM (VCV) jumping DiatonicCV around its scale so the chord wanders on its own but stays diatonic — and then makes one decisive change that lands it somewhere completely different. Where session 28 ran that chord through an arpeggiator to unroll it into a line, here the DiatonicCV Chord Out goes straight into the Sine VCO’s V/OCT as the pitch input. The chord arrives as a single polyphonic cable, the Surge VCO spins up one voice per channel, and all the notes sound at once — the chord played as a cluster rather than spelled out in time. It’s the mirror image of the arpeggiated voice: the same wandering diatonic harmony, but held as a stack instead of stepped through.
An LFO on the feedback turns the chord to static. The sine VCO’s FEEDBACK folds harmonics into the tone — clean at zero, buzzy and near-distorted wide open, the same control that brightened the arp’s accents. Here a WT LFO (VCV’s wavetable LFO — an LFO whose shape is read from a wavetable, with WT POS scanning through that table to pick the waveform) modulates that feedback continuously, so the harmonic content never sits still. With several pitches feeding back at once and the feedback amount sweeping up and down, the tone dissolves from a roughly-pitched chord into a wash of buzzing, granular noise and re-forms again on the LFO’s cycle — pitched static: you can still hear the chord’s notes underneath, but veiled in a noisy, broken-up texture, the way a detuned radio holds a station inside the hiss. The scope shows it directly — not a clean wave but a jagged, fractured one.
When the LFO sits low the feedback eases off and the chord re-forms into something closer to a clean, reedy pad; as it rises the feedback piles on until the pitches break up into grit — so the whole voice breathes between tone and noise at the LFO’s rate. A slow LFO makes that a long swell from clear to noisy and back; speed it up and the chord shimmers, fluttering between pitch and static several times a second.
The envelope shapes it through the Stereo Strip. A VC ADSR (Befaco) shapes the voice’s amplitude, but rather than opening a VCA directly it controls the LEVEL of a STEREO STRIP (Befaco) — the stereo VCA-and-output stage the VCO runs through, with its own PAN and LEVEL, the same role it played in session 28. Gated in step with the chord changes, the envelope keeps the static from being a constant drone: each gate swells the chord in and out, and the A/D/S/R sliders set whether that’s a slow pad-like bloom or a sharper, more percussive articulation of the noise.
A pinged filter, scattered by chance

The third voice crosses over into the session 30 half of the patch: a pinged filter again, the same Audible Instruments liquid filter struck so it rings at its cutoff like a bell. The shaping around it is the chain that voice built — the strike pings the filter and I take its bandpass BP2 output for a focused ring; a slow LFO modulates the filter’s frequency so each ping lands wherever the cutoff has drifted, tracing a melodic contour since cutoff is the pitch of a pinged filter; a second VCF with an ADSR EG on its cutoff opens in lockstep with each hit to brighten the attack and darken the tail; and a Chronoblob2 stereo delay throws the result into a ping-ponging bounce between left and right. What’s new this time is how the strikes get timed and chosen.
A clock divider sets the pulse. Instead of a trigger sequencer, the strikes come from a CLOCK DIV. (Count Modula) — it takes the master clock and hands back a column of divisions, each output a different slower multiple (every 2nd, 3rd, 4th, 5th… pulse, including odd primes like 7, 11 and 13). Tapping one of those outputs gives this voice a strike rate that’s a clean division of the shared tempo — slower and sparser than the arpeggio, but locked to the same grid.
A Bernoulli gate adds the chance. The new module is the bernoulli gate (VCV), a probabilistic router — a coin flip you can weight. Each trigger arriving at its IN is sent to one of two outputs, A or B, and the p knob sets the odds: turned fully one way every trigger goes to A, fully the other way every trigger goes to B, and at noon it’s an even 50/50 toss decided fresh on every pulse. Here only OUT A carries on to the ping — OUT B is left unpatched, a rest — so each flip either lands a strike or drops it. That turns the steady divided pulse into a broken, probabilistic rhythm: the pings fire on some pulses and fall silent on others, sparse and never quite repeating, yet every strike that does sound still lands on the clock’s grid. The ping-pong itself is the Chronoblob2 behind it — each surviving strike thrown into echoes that hop between left and right.
The full patch
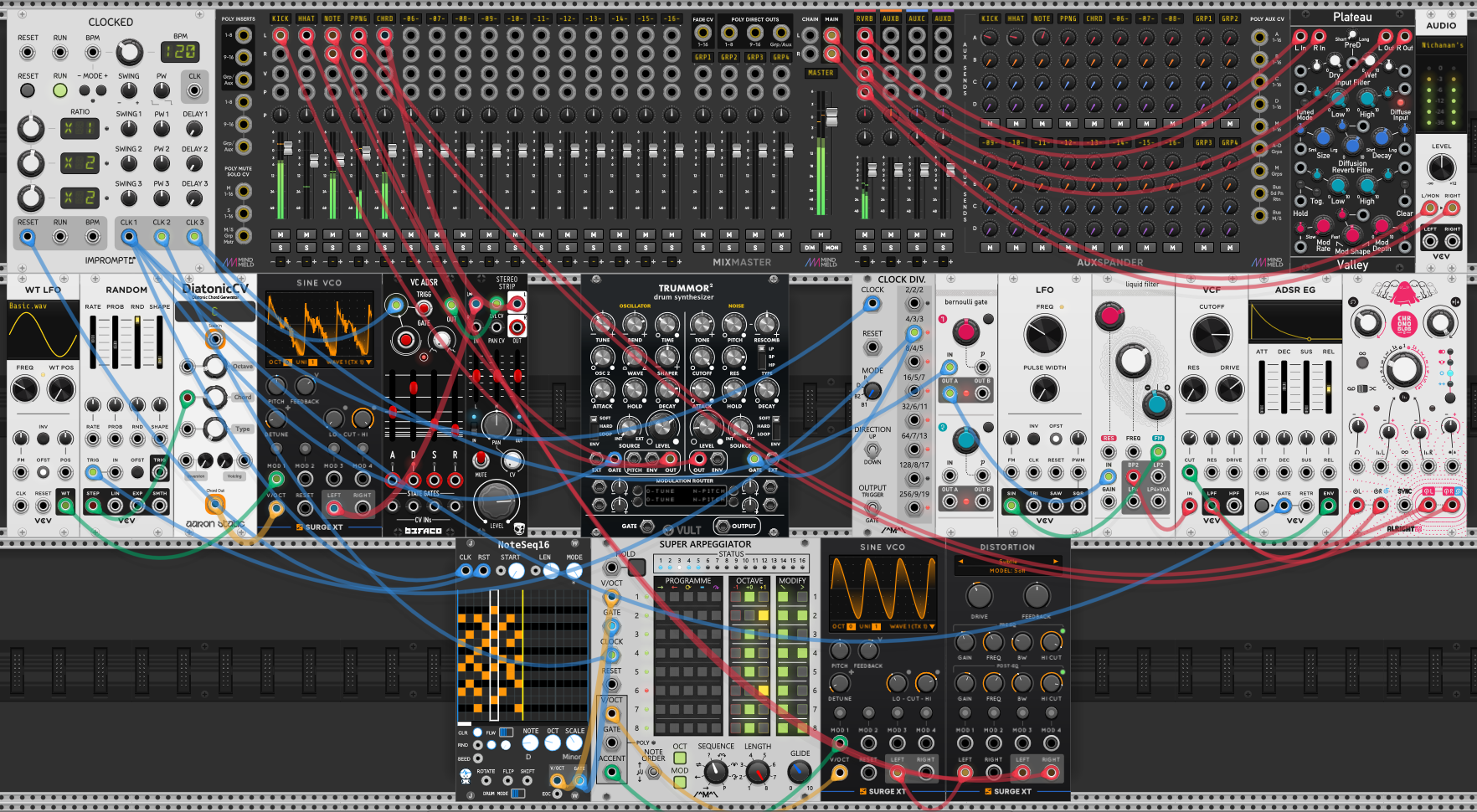
To give the three voices a rhythmic floor, a TRUMMOR² (Vult) holds down a kick and hihat — its OSCILLATOR section tuned as the kick, its NOISE section as the hat — deliberately plain support so the ear has a steady grid to hear the arpeggio, the static chord and the scattered pings against. Everything runs from one CLOCKED (Impromptu) at 120 BPM: the arpeggiator’s steps, the chord’s random changes and the pinged voice’s clock divider all draw from that single master clock, so the three studies share one tempo even as each moves at its own rate against it.
The real new ground this session is the mix. Where session 30 gave every voice its own dedicated reverb, here all five channels land on a single MIXMASTER (MindMeld) — one labelled fader per component (KICK, HHAT, NOTE for the arp, PPNG for the pings, CHRD for the static chord) — and the reverb is shared through its AUXSPANDER expander.
Aux sends — one reverb, many depths. The AuxSpander bolts four aux send buses onto the mixer (the first labelled RVRB), and every channel gets its own send knob into each bus. An aux send is a parallel tap: it siphons off an adjustable amount of a channel’s signal, sums those taps across all the channels, and routes the sum to one effect — a single Plateau (Valley) reverb sitting on the RVRB bus — whose wet return is mixed back in. So instead of a reverb per voice there’s one reverb that every voice dips into by a different amount: the arp can stay nearly dry while the pings trail long and the static chord washes out, each depth set by that channel’s own RVRB send knob rather than its own reverb module. That’s the distinction between an insert — an effect inline in one channel’s path, like the distortion on the arp — and a send — a shared effect that many channels feed in parallel. The send is how you give a whole mix one coherent space while still controlling how deep each element sits in it, and the MAIN mix runs out to AUDIO.
Reflection
This session didn’t add a sound so much as a room. Each voice already existed — the arpeggio, the chord, the pinged filter — so the work here wasn’t synthesis but arrangement: getting three busy, independent things to share one space without cluttering it. What caught me off guard was how much of that turned out to be a mixing problem rather than a patching one. The voices didn’t need redesigning; they needed a common reverb to sit in and faders to set their hierarchy, and the moment they had both they stopped reading as three demos and started reading as one track.
The other thing the session drove home is how much a chord’s role lives in the treatment rather than the notes: unrolled through an arpeggiator it’s a forward, melodic line, but held under swept feedback it collapses into pure background texture — the same gesture, a chord, doing opposite jobs depending only on how it’s voiced. Next time I want to lean on that on purpose: fewer separate ideas, more of one idea voiced several ways, and let the mix decide which version sits in front.